Online NHNCloud Verification Numbers for Instant SMS
NHNCloud SMS verification numbers are often used through online inboxes for quick OTP testing, but shared numbers are not always reliable for important NHNCloud verification. Since many users may use the same number, it can become overused, blocked, or flagged, leading to OTP delays or failed SMS delivery.For critical NHNCloud actions such as sign-up, log-in, re-login, account recovery, or security checks, it’s better to choose a Rental number with repeat access or a Private/Instant Activation number. These options usually offer better delivery rates, greater privacy, and higher reliability than public shared inbox services.

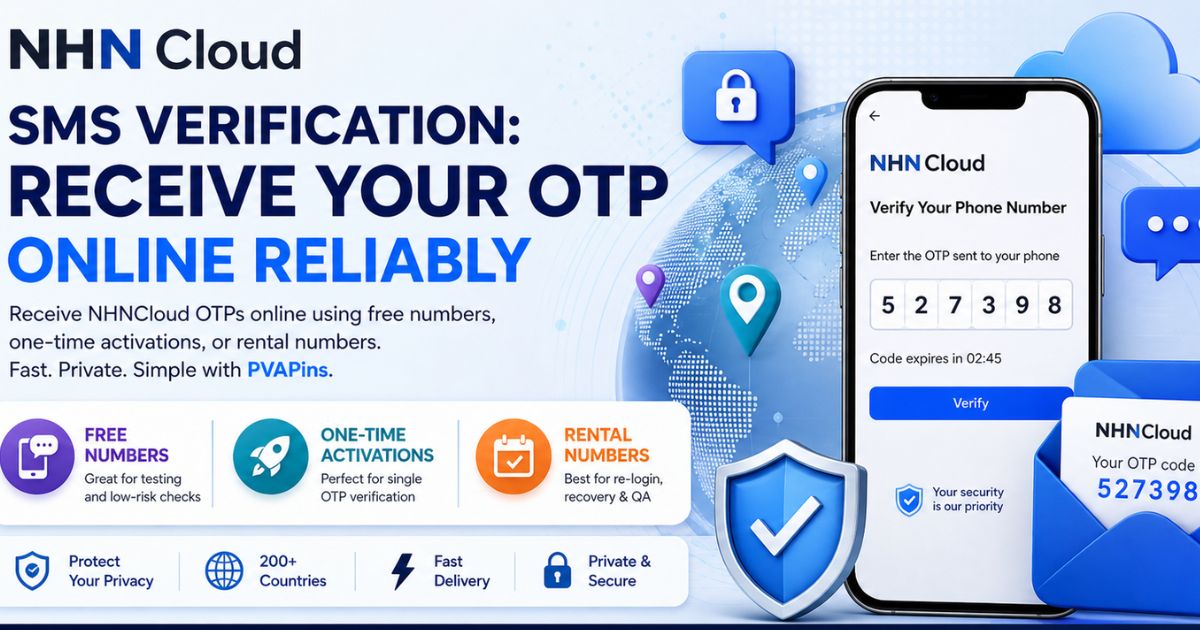
How it works
Pick your NHNCloud number type.
If you’re only testing, you can try a free/shared inbox. For higher success, especially if you may need to log in again later, choose Instant Activation for a private number or Rental for repeat access. These options are usually more reliable than shared inboxes for NHNCloud SMS verification.
Choose the country + number.
Select the country you need, grab a number, and copy it carefully. Paste it in a clean format: +CountryCodeNumber, for example, +82101234567, with or digits-only if the NHNCloud form does not accept the plus sign. Avoid spaces, dashes, brackets, and extra leading zeros.
Request the OTP on NHNCloud.
Enter the number on NHNCloud during signup, login, relogin, account recovery, or security verification. Tap Send code, then avoid repeated requests. Use one request, wait 60–120 seconds, and resend only once if needed.
Receive the SMS on PVAPins.
The NHNCloud OTP code will appear in your PVAPins inbox. Copy the code and enter it back on NHNCloud right away, because OTP codes can expire quickly.
OTP not received? Do this
- Wait 60–120 seconds (don't spam resend)
- Retry once → then switch number/route
- Keep device/IP steady during the flow
- Prefer private routes for better pass-through
- Use Rental for re-logins and recovery
Wait 60–120 seconds, then resend once.
Confirm the country/region matches the number you entered.
Keep your device/IP steady during the verification flow.
Switch to a private route if public-style numbers get blocked.
Switch number/route after one clean retry (don't loop).
Free vs Activation vs Rental (what to choose)
Choose based on what you're doing:
Quick number-format tips (avoid instant rejections)
Most NHNCloud OTP verification failures are formatting issues, not inbox issues. Always use the international format with the country code and full number, and keep it clean.
Do this:
Use country code + digits
No spaces, no dashes, no brackets
Don’t add an extra leading 0 at the start
Copy and paste the number exactly as shown
Best default format:
+CountryCodeNumber
Example: +821012345678
If the form is digits-only:
CountryCodeNumber
Example: 821012345678
Simple OTP rule:
Request once → wait 60–120 seconds → resend only once.
Inbox preview
| Time | Country | Message | Status |
|---|---|---|---|
| 2 min ago | USA | Your verification code is ****** | Delivered |
| 7 min ago | UK | Use code ****** to verify your account | Pending |
| 14 min ago | Canada | OTP: ****** (do not share) | Delivered |
FAQs
Quick answers people ask about Nhncloud SMS verification.
Is receiving an NHNCloud SMS code legal?
Yes, PVAPins receiving an SMS code online can be legal when it’s used for your own legitimate account actions, testing, privacy-friendly verification, or business workflows. You still need to follow the platform’s terms and your local regulations.
Why haven't I received my NHNCloud SMS code?
Your code may not arrive because the number is unsupported, the country code is wrong, the SMS route is delayed, or too many codes were requested too quickly. Check the format first, wait briefly, then try a cleaner one-time activation or rental if needed.
What phone number format should I use?
Use the full international format with the correct country code unless the verification form clearly asks for a local format. Avoid extra spaces, symbols, or missing digits when copying the number.
Should I use a one-time activation or a rental?
Use a one-time activation if you only need one OTP for a single verification step. Use a rental if you may need the same number again for login, recovery, repeated testing, or ongoing access.
Can I use a free number for verification?
A free number can work for basic testing or low-risk checks, but it may be public, reused, or less suitable for recovery-sensitive accounts. If privacy or future access is a concern, a one-time activation or rental is usually the smarter option.
What should I not use temporary numbers for?
Don’t use temporary numbers for spam, fraud, impersonation, harassment, evasion, account abuse, or breaking platform rules. Use them only for legitimate verification, privacy, testing, and business workflows.
What should I do if my OTP expires?
Request a fresh code after waiting a reasonable amount of time, then enter the newest code only. Old codes often stop working after a newer OTP is issued.
Read more: Full Nhncloud SMS guide
Open the full guide
Need to receive an NHNCloud OTP without putting your personal number into every verification form? You’re in the right place.This guide is for people who need a clean way to receive an SMS code for signup, login, recovery, testing, or business workflows. It’s also for anyone who wants to understand when a free number is enough, when a one-time activation makes more sense, and when renting a number is the safer call.
PVAPins is not affiliated with NHNCloud. Please follow each app’s terms and local regulations.
Quick Answer
You can receive an NHNCloud OTP online by choosing a temporary, virtual, one-time, or rental number and checking the connected inbox.
Free numbers are useful for simple testing, but they’re usually not the best choice for important accounts.
One-time activations work well when you only need one code.
Rentals are better when you may need the same number again for login, recovery, or repeated QA.
If the code doesn’t arrive, check the country code, number format, inbox timing, and number type before requesting more OTPs.
What Is NHNCloud SMS Verification?
SMS verification service is the process of receiving a short one-time code by text message and entering it to confirm an account action. That action might be a sign-up, a login, a phone confirmation, a security update, or an account recovery. The point is simple: the platform wants to confirm that you can access the phone number used in the verification flow. For you, the real decision is which number type fits the job: personal, temporary, virtual, one-time activation, or rental.An OTP is only useful for that verification moment. It doesn’t solve future recovery unless you can access the same number again.
When NHNCloud may ask for an SMS code
NHNCloud may ask for an SMS code when you create an account, sign in from a new setup, confirm a phone number, update security details, or recover access. The exact trigger depends on the verification flow you’re using.
Common situations include:
New account signup
Login verification
Phone number confirmation
Security or profile updates
Account recovery checks
SMS delivery testing in a development or QA workflow
Keep the inbox open before you request the code. OTPs can expire quickly, and honestly, missing a fresh code by a few minutes is annoying.
Why OTP verification matters
OTP verification helps confirm that the person acting on the request can access the phone number associated with the request. It may also support account protection, reduce fake signups, and help with recovery flows.For privacy-focused users, receiving SMS online can reduce exposure of their personal numbers. For teams, it can make testing easier without asking employees to use their own phones.The number type matters. A free public number can be fine for low-risk testing, while a rental is usually the better pick when future access matters.
Quick Start: How to Receive NHNCloud OTP Online
To receive an NHNCloud OTP online, choose a suitable number type, copy the number into the verification field, request the SMS code, then check the connected inbox. Enter the newest OTP as soon as it arrives.For a direct flow, start with PVAPins to receive SMS online, then choose the option that fits your use case.
A clean OTP flow is simple: pick the number first, request the code once, wait briefly, then enter the latest code.
Choose a number type
Start by choosing the country and number type that fits your goal. Country selection can affect routing, while number type affects privacy, repeat access, and recovery risk.
Use this simple guide:
Choose a free number for basic testing or low-risk checks.
Choose a one-time activation when you only need one OTP.
Choose a rental number if you may need it again.
Choose a private/non-VoIP option when privacy and continuity matter more.
Avoid public numbers for accounts you may need to recover later.
PVAPins supports numbers across 200+ countries, which is useful when you need to test different regions or choose a number that better matches your workflow.
Request the OTP
Copy the selected number and paste it into the phone verification field. Before requesting the code, check that the country code is correct.
A smoother process looks like this:
Select your country and number type.
Copy the full number with the country code.
Paste it into the verification form.
Request the OTP.
Open or refresh the matching PVAPins inbox.
Copy the code exactly as shown.
Don’t keep smashing the resend button. Multiple fast requests can cause delays, expire older codes, or make the verification flow more complex than necessary .
Enter the code before it expires.
Most OTPs are short-lived. Enter the code as soon as it appears, and copy only the digits required by the verification screen.If you request a new code, use the newest one. Older codes often stop working after a replacement has been issued.A delayed code is not always a failed code. Give the inbox a short window to update before switching numbers or requesting another OTP.
Free vs One-Time vs Rental Numbers for NHNCloud
Free numbers are useful for simple testing, one-time activations are better for a single OTP, and rental numbers are best when you may need the same number again. The right choice depends on whether this is a quick check or something you’ll need to access later.You can start with free numbers for SMS testing, then move to a one-time activation or rental if the account or workflow matters more.Don’t choose only by price. Choose by risk, privacy, and whether you’ll need the number again.
When a free number makes sense
A free number makes sense when you’re a testing basic SMS receipt, checking whether a route works, or handling a low-risk flow where future access is not important.Free numbers are convenient, but they may be public. That means messages could appear in a shared inbox, and the number may have been used before.
Use free numbers when:
You’re testing whether SMS delivery works.
The account is not sensitive.
You don’t need future recovery access.
You’re comparing country behavior.
You understand the privacy tradeoff.
A free public inbox is useful for testing. It’s not ideal for account access you can’t afford to lose.
H3: When a one-time activation is better
A one-time activation is better when you need a cleaner single-use OTP flow. It’s a better fit when you want one code without relying on a public inbox.
This is usually the middle option when a free number doesn’t receive the code or feels too exposed. It’s still not the same as a long-term number, though.
Use a one-time activation when:
You only need one OTP.
You don’t expect repeated login checks.
Free numbers are not receiving SMS.
You want a more focused code-receiving flow.
You don’t need long-term access to the same number.
When to rent a number
Rent a number when you may need the same phone number again for re-login, account recovery, repeated verification, or longer testing workflows. Rentals give you ongoing access during the rental period.PVAPins rentals are useful when continuity matters more than the lowest upfront cost. For ongoing access, you can rent a private number instead of relying on a one-time or public number.
Use a rental when:
You may need future login verification.
You want access to the same number during the rental window.
The account has recovery value.
You’re testing repeated SMS flows.
You prefer a more private option than a public inbox.
Temporary Phone Number for NHNCloud: What to Know First
A disposable phone number can help you receive an OTP without using your personal phone number. It works best for legitimate testing, privacy-friendly verification, or short-term SMS receipt.Temporary numbers are practical, but they’re not magic. Country choice, number type, reuse history, and platform acceptance can all affect whether a code arrives.Use temporary numbers for convenience and privacy, not for abuse, impersonation, spam, or breaking platform rules.
Benefits of temporary numbers
A temporary number gives you a separate number for receiving SMS online. That helps you avoid entering your personal phone number into every verification form.
Benefits include:
Less exposure of your personal phone number
Faster setup for short-term verification
Easier testing across different countries
Better separation between personal and work testing
Flexible use for one-time OTP receipt
For privacy-friendly workflows, that separation is the big win. You can receive a code without making your personal number the default option for every account or test.
Limits and recovery risks
Some platforms may reject temporary, public, or heavily reused numbers. SMS can also fail due to country mismatch, incorrect format, delayed delivery, expired codes, or unsupported number types.Temporary numbers are not ideal when long-term recovery is at stake. If the platform asks for the same number later and you no longer have access, account recovery may get messy.Use a rental when the account may ask for another OTP later. A reusable number is often the safer choice for recovery-sensitive workflows.
Virtual Number for NHNCloud Verification
A virtual number for NHNCloud lets you receive SMS via an online inbox or app rather than a physical SIM. It can be useful for privacy, testing, business workflows, and short-term account verification.Virtual numbers may be temporary, one-time, or rented, depending on the service option. The key is matching the number type to the verification job.A virtual number is not automatically better or worse than a SIM. It depends on the use case, country, number quality, and whether future access matters.
How virtual numbers receive SMS
Virtual numbers receive incoming text messages and display them in an online inbox. You request the verification code, then check the inbox connected to that number.
The basic process is:
Select a virtual number.
Enter it in the verification field.
Request the SMS code.
Open the inbox.
Copy the OTP.
Enter it before it expires.
You can also use thePVAPins Android app if you prefer checking messages from your phone.
Why country and number quality matter
Country and number quality can affect SMS delivery. Some routes work better than others, and some platforms may filter certain number types more often.
A public virtual number may work for a quick test. A private or rental number is usually better when account continuity or privacy is a concern.
The better question isn’t “Will any virtual number work?” It’s “Which number type fits this verification need?”
NHNCloud SMS Not Received: Common Causes and Fixes
If your NHNCloud SMS is not received, the issue may be a wrong country code, an unsupported number, an SMS delay, an expired OTP, or too many resend attempts. Start with the simple checks before switching numbers.A failed OTP is usually not a disaster. Most issues come down to formatting, timing, number type, or repeated code requests.
If a free number keeps failing, switch to a cleaner one-time activation via SMS online.
Wrong number format
A simple formatting mistake can stop the code from arriving. Make sure the number matches the country selected in the verification form.
Check for:
Missing country code
Wrong country selected
Extra spaces or symbols
Leading zero issues
Copy-paste mistakes
Incomplete number entry
Use the full international format unless the form clearly asks for a local format.
Unsupported or overused number
Some numbers may be unsupported, filtered, or already overused. This can happen more often with public inbox numbers.
Try this troubleshooting flow:
Switch to another number from the same country.
Try a different country if appropriate.
Move from a free number to a one-time activation.
Use a rental if the account may need future access.
Avoid repeatedly requesting codes on the same failed number.
If the same number fails repeatedly, changing the number type is usually smarter than repeatedly hitting the resend button.
Delayed, expired, or resent OTP
Sometimes an OTP arrives late. If you request another code too quickly, the earlier code may become invalid.
Use this cleaner flow:
Wait briefly after requesting the code.
Refresh the inbox.
Confirm the number is correct.
Request a fresh code only if needed.
Enter the newest code, not an older one.
The newest OTP is usually the one that matters. Old codes often fail after a resend.
How to Verify an NHNCloud Account Safely
To verify an NHNCloud account safely, use a number you’re allowed to access, request the OTP through the normal verification flow, and enter the code only for your own legitimate account action. Online numbers should be used for privacy, testing, and business workflows.Don’t use temporary or virtual numbers for impersonation, spam, fraud, harassment, account abuse, evasion, or breaking platform rules. That’s not a grey area it’s the wrong use case.
Safe verification means convenience plus responsibility.
Step-by-step safe verification flow
Follow the standard verification path and keep the process simple:
Open the official signup, login, phone confirmation, or recovery flow.
Choose the PVAPins number type that best suits your needs.
Copy the number with the correct country code.
Paste it into the verification field.
Request the OTP.
Check the matching inbox.
Enter the newest code before it expires.
Save recovery details securely if the account matters.
For important accounts, think beyond the first OTP. Future access is where rentals often make more sense than one-time codes.
Use cases that stay within the rules
Good use cases include privacy-friendly verification, SMS delivery testing, QA workflows, business testing, and separating personal numbers from account forms.
Safe use cases include:
Testing SMS delivery
Verifying your own account action
Reducing personal number exposure
Running QA on signup or login flows
Managing business verification workflows
Checking OTP behavior across countries
Unsafe use cases include spam, fraud, impersonation, harassment, account abuse, ban evasion, and platform rule violations.
NHNCloud OTP Testing for Developers and Teams
NHNCloud OTP testing is useful for developers, QA teams, and businesses that need to test SMS flows without exposing personal numbers. A temporary number can help with quick checks, while rentals are better for repeated test cycles.For larger workflows, API-ready stability and reusable number access can reduce friction. The goal is to create a repeatable testing process, not a messy one-off scramble.Teams should document which number type they used, which country they tested, and whether the OTP arrived on the first request or after a retry.
Testing SMS delivery without exposing personal numbers
Using personal numbers for QA can get messy fast. It mixes private contact details with work testing, making repeated verification harder to manage.
A cleaner testing setup can include:
Free numbers for basic route checks
One-time activations for single OTP tests
Rentals for repeated signup, login, or recovery checks
Different countries for regional delivery checks
Shared documentation for test results and the number type used
PVAPins supports 200+ countries, enabling teams to test SMS behavior across regions without relying on personal devices.
Why reusable rentals help longer QA workflows
Reusable rentals are useful when a test flow may ask for the same number again. This matters for repeated login, recovery, retesting, or staged account flows.
Rentals can help teams:
Repeat the same verification flow
Check re-login behavior
Test account recovery prompts
Avoid changing numbers too often
Keep a more consistent QA process
One-time activations are fine for single checks. Rentals are better when continuity matters.
Can You Use NHNCloud Without Your Personal Number?
You may be able to use an online number for NHNCloud verification when your use case is legitimate, and the number type is accepted. This can reduce exposure of your personal phone number.The tradeoff is future access. If the account may ask for the same number later, choose a rental or consider using a long-term number you can reliably access.For short-term testing, online numbers are convenient. For long-term account ownership, recovery access matters more.
Privacy-friendly verification
Privacy-friendly verification means using a number that helps you receive an OTP without making your personal phone number part of every signup, test, or account flow.
This can help with:
Reducing personal number exposure
Separating personal and work activity
Running short-term verification checks
Testing SMS flows across countries
Avoiding unnecessary use of a private SIM
A public inbox can be convenient, but it is not private. If privacy matters, use a private or rental option.
When your own number may be better
Your own number may be better when the account is highly important, tied to identity, or likely to require long-term recovery through the same number.
Be cautious with temporary numbers if:
The account holds sensitive personal data.
You expect ongoing 2FA prompts.
The platform requires the same number for recovery.
Losing access to the number could lock you out.
The account is for long-term personal or business use.
Online numbers are useful tools. They are not a replacement for good account recovery planning.
NHNCloud Verification FAQ: What to Know Before You Start
Most verification questions come down to the type of number, timing, formatting, and future access. Before requesting the code, decide whether you need a free number, one-time activation, or rental.A little planning can prevent expired codes, failed messages, and recovery headaches later. The right PVAPins option depends on whether you’re testing, verifying once, or keeping access for future checks.PVAPins supports multiple payment options, including Crypto, Binance Pay, Payeer, GCash, AmanPay, QIWI Wallet, DOKU, Nigeria & South Africa cards, Skrill, and Payoneer.
Timing, reuse, and recovery
OTP timing matters because verification codes are usually short-lived. Keep the inbox open before requesting the code, then enter it as quickly as possible.Reuse matters because one-time numbers are often not designed for long-term use. If you’re asked for the same number later and you can’t access it, account recovery may become harder.For recovery-sensitive workflows, rentals are the safer choice. They give you access to the same number during the rental period.
Choosing the right PVAPins option
Choose based on your actual need, not just the cheapest option.
Use free sms verification for simple testing.
Use one-time activations for a single OTP.
Use rentals for re-login, recovery, or repeated verification.
Use private/non-VoIP options when privacy and number quality matter.
Use the PVAPins FAQs if you need help with delivery or account setup questions.
Key Takeaways:
SMS verification is a normal OTP process used to confirm account actions.
Free numbers are useful for testing, but they may not be the best for private or recovery-sensitive accounts.
One-time activations are better for single-use verification.
Rental numbers are best when you may need the same number again.
If SMS doesn’t arrive, check format, country, timing, and number type before requesting more codes.
Conclusion
NHNCloud SMS verification is simple when you choose the right number type before requesting the code. Free numbers are good for quick testing; online SMS receivers are better for a single OTP; and rentals are the safer choice when you may need the same number again for login, recovery, or repeated QA.If your NHNCloud SMS code doesn’t arrive, don’t keep resending it right away. Check the country code, number format, inbox timing, and whether the number type is suitable. For privacy-friendly verification and testing, PVAPins offers flexible options across free numbers, one-time activations, and rentals so that you can receive your OTP with less friction.Need ongoing access for re-login or recovery? Use PVAPins Rentals to keep access to the same number during your rental period.
Compliance note: PVAPins is not affiliated with the app/website or platform. Please follow each app/website’s terms and local regulations.
Last updated:
Top Countries for Nhncloud
Get Nhncloud numbers from these countries.




Ready to Keep Your Number Private in Nhncloud?
Get started with PVAPins today and receive SMS online without giving out your real number.
Try Free NumbersGet Private Number
Written by Team PVAPins
The PVAPins Team is made up of writers, privacy researchers, and digital security professionals who have been working in the online verification and virtual number space since 2018. Collectively, our team has hands-on experience with hundreds of virtual number platforms, SMS verification workflows, and privacy tools — and we use that experience to produce guides that are genuinely useful, not just keyword-stuffed articles.
At PVAPins.com, we cover virtual phone numbers, burner numbers, and SMS verification for over 200 countries. Our content is built on real testing: before any tool, service, or method appears in one of our guides, a member of our team has tried it personally. We fact-check our own recommendations regularly, update outdated content, and remove anything that no longer works as described.
Our team includes writers with backgrounds in cybersecurity, digital marketing, SaaS product management, and IT administration. That mix of perspectives means our content serves a wide range of readers — from individuals protecting their personal privacy online, to developers building verification flows, to business owners managing multiple accounts at scale.
We're committed to transparency: we clearly disclose how PVAPins works, what our virtual numbers can and can't do, and who our guides are designed for. Our goal is to be the most trusted, most accurate resource for anyone looking to understand and use virtual phone numbers safely and effectively — wherever they are in the world.